Social science is hard. One motivation for starting this blog is to have a place where I can sift through various social science theories/studies/facts and figure out which are credible and which should be disregarded. I’m hoping that converting my thoughts about various social science theories (and the public policy and moral frameworks they inform) into words will help me clarify my thinking and expose half-baked ideas and intuitions. Indeed, writing something down forces a minimum level of clarity, logic, and persuasiveness.
My focus on social science isn’t just because it’s difficult, since STEM fields are plenty challenging in their own right. There is also my personal interest in social science (especially economics, which was one of my majors in college), and the fact that findings in social science are highly relevant to public policy debates (many of which I am personally invested in).
But my emphasis on social science and desire to interrogate its theories in these posts is also due to a recognition that social science is actually harder than other kinds of academic inquiry. Unlike researchers in the natural sciences, those in social science are studying largely invisible social phenomena that are imprecisely defined and measured. They usually resort to using observational data (data gathered passively rather than for the express purpose of academic research) and can rarely run the tightly-controlled experiments commonplace in some natural science fields.
Here is how Nature editors described some of the challenges facing social scientists in a piece responding to Congressional Republicans’ 2012 push to end NSF funding for political science research (emphasis mine):
The social sciences are an easy target for this type of attack because they are less cluttered with technical terminology and so seem easier for the layperson to assess. …
Part of the blame must lie with the practice of labelling the social sciences as soft, which too readily translates as meaning woolly or soft-headed. Because they deal with systems that are highly complex, adaptive and not rigorously rule-bound, the social sciences are among the most difficult of disciplines, both methodologically and intellectually. They suffer because their findings do sometimes seem obvious. Yet, equally, the common-sense answer can prove to be false when subjected to scrutiny. There are countless examples of this, from economics to traffic planning.
And here is Sociologist Rene Bekkers listing the reasons he thinks social science is especially challenging:
1. No Laws
All we have is probabilities.
2. All Experts
The knowledge we have is continuously contested. The objects of study think they know why they do what they do.
3. Zillions of Variables
Everything is connected, and potentially a cause – like a bowl of well-tossed spaghetti.
4. Many Levels of Action
Nations, organizations, networks, individuals, time all have different dynamics.
5. Imprecise Measures
Few instruments have near perfect validity and reliability. Conclusion
Social science is not as easy as rocket science. It is way more complicated.
Now, that social science is difficult is not the only reason it’s worth expending considerable effort scrutinizing its findings and theories (rather than taking them at face value). There is also the specter of shoddy methodology and, far too often, something akin to outright fraud.
In other words, large swaths of social science research are unreliable due to avoidable failings on the part of the researchers. FantasticAnachronism describes the situation in grim detail:
There's a popular belief that weak studies are the result of unconscious biases leading researchers down a "garden of forking paths". Given enough "researcher degrees of freedom" even the most punctilious investigator can be misled.
I find this belief impossible to accept. The brain is a credulous piece of meat but there are limits to self-delusion. Most of them have to know. It's understandable to be led down the garden of forking paths while producing the research, but when the paper is done and you give it a final read-over you will surely notice that all you have is a n=23, p=0.049 three-way interaction effect (one of dozens you tested, and with no multiple testing adjustments of course). At that point it takes more than a subtle unconscious bias to believe you have found something real. And even if the authors really are misled by the forking paths, what are the editors and reviewers doing? Are we supposed to believe they are all gullible rubes?
…
Even when they do accuse someone of wrongdoing they use terms like "Questionable Research Practices" (QRP). How about Questionable Euphemism Practices?
When they measure a dozen things and only pick their outcome variable at the end, that's not the garden of forking paths but the greenhouse of fraud.
When they do a correlational analysis but give "policy implications" as if they were doing a causal one, they're not walking around the garden, they're doing the landscaping of forking paths.
When they take a continuous variable and arbitrarily bin it to do subgroup analysis or when they add an ad hoc quadratic term to their regression, they're...fertilizing the garden of forking paths? (Look, there's only so many horticultural metaphors, ok?)
If you’re not familiar with the so-called “Replication Crisis” and the way researchers routinely produce spurious findings, I encourage you to read this piece by Scott Alexander (part of a larger series on the reliability of scientific research). Here's an enlightening excerpt about a darkly revealing psychology paper, beginning with four tricks to make almost any research yield “statistically significant” results (practices that are employed by a shamefully large number of actual researchers):
1. Measure multiple dependent variables, then report the ones that are significant. For example, if you’re measuring whether treatment for a certain psychiatric disorder improves life outcomes, you can collect five different measures of life outcomes – let’s say educational attainment, income, self-reported happiness, whether or not ever arrested, whether or not in romantic relationship – and have a 25%-ish probability one of them will come out at significance by chance. Then you can publish a paper called “Psychiatric Treatment Found To Increase Educational Attainment” without ever mentioning the four negative tests.
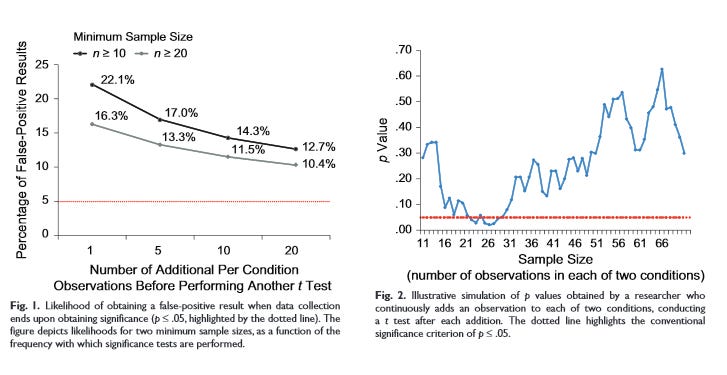
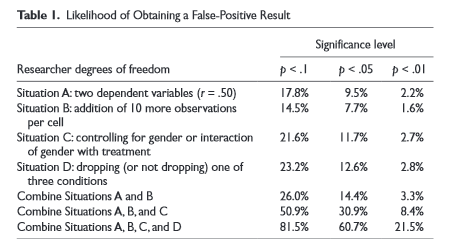
2. Artificially choose when to end your experiment. Suppose you want to prove that yelling at a coin makes it more likely to come up tails. You yell at a coin and flip it. It comes up heads. You try again. It comes up tails. You try again. It comes up heads. You try again. It comes up tails. You try again. It comes up tails again. You try again. It comes up tails again. You note that it came up tails four out of six times – a 66% success rate compared to expected 50% – and declare victory. Of course, this result wouldn’t be significant, and it seems as if this should be a general rule – that almost by the definition of significance, you shouldn’t be able to obtain it just be stopping the experiment at the right point. But the authors of the study perform several simulations to prove that this trick is more successful than you’d think:
3. Control for “confounders” (in practice, most often gender). I sometimes call this the “Elderly Hispanic Woman Effect” after drug trials that find that their drug doesn’t have significant effects in the general population, but it does significantly help elderly Hispanic women. The trick is you split the population into twenty subgroups (young white men, young white women, elderly white men, elderly white women, young black men, etc), in one of those subgroups it will achieve significance by pure chance, and so you declare that your drug must just somehow be a perfect fit for elderly Hispanic women’s unique body chemistry. This is not always wrong (some antihypertensives have notably different efficacy in white versus black populations) but it is usually suspicious.
4. Test different conditions and report the ones you like. For example, suppose you are testing whether vegetable consumption affects depression. You conduct the trial with three arms: low veggie diet, medium veggie diet, and high veggie diet. You now have four possible comparisons – low-medium, low-high, medium-high, low-medium-high trend). One of them will be significant 20% of the time, so you can just report that one: “People who eat a moderate amount of vegetables are less likely to get depression than people who eat excess vegetables” sounds like a perfectly reasonable result.
Then they run simulations to show exactly how much more likely you are to get a significant result in random data by employing each trick:
The image demonstrates that by using all four tricks, you can squeeze random data into a result significant at the p < 0.05 level about 61% of the time.
Due to these research practices, as well as other distortions like publication bias, the existing social science literature is far less reliable than we would expect even if we concede that the research itself is incredibly challenging.
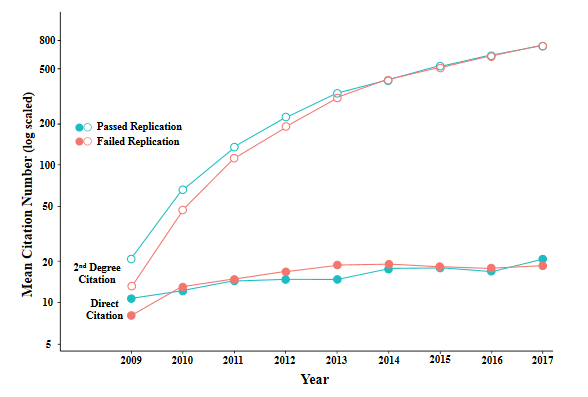
However, there is a real question as to whether a non-expert blogger with only an undergraduate education (in one social science, economics) is really equipped to identify credible research. But professional researchers themselves don’t seem to be very good at this either. The graph below shows how papers that *failed* to replicate are cited just as often as papers that passed replication.
From the FantasticAnachronism piece linked to above.
One workaround here is to use broadly applicable rules of thumb to assess a theory/finding. Regardless of the specific field, if a paper has a small sample size, a p-value close to 0.05, uses regression analysis and attempts to “control for confounders,” has small effect sizes, and/or conducts extensive subgroup analysis/turns continuous variables into categorical ones, it should probably be regarded as low-quality.
Likewise, papers that have large sample sizes, very small p-values, large effect sizes, etc.; use a randomized controlled trial methodology or another method capable of establishing causality; correct for multiple comparisons; pre-register their study designs so they can’t adjust their methods as they go (as described by Scott Alexander above); etc. are more likely to have reliable findings. Again, you can draw these conclusions based on just a few metrics (sample size (n), significance level (p), etc.) even if you know little about the subject matter under study.
So I definitely want to use this as a space to examine elements of social science (especially economics), and use theories and evidence I deem credible to understand the institutions and forces most relevant in the world of 2021. I also want to try my hand at making predictions, and hope to weigh in on public policy debates and current events based on my understanding of the relevant theory, literature, and (sometimes) my own analysis. But I have another motivation for starting this blog that I want to touch on briefly.
Blogs as a genre of writing are situated somewhere between longer-form essays/articles/op-eds (which do a good job articulating things carefully and persuasively at the expense of greater time & effort by the author and fewer opportunities for reader engagement), and social media posts (which basically do the opposite). They strike a nice balance between quantity and quality of posts.
They also allow for iterative improvement of one’s ideas (blog post idea —> writing the post itself and clarifying/refining my thoughts —> after posting, engaging with reader feedback/criticism —> a new, “better” idea that incorporates what I learned through writing and reading responses to the first post —> rinse and repeat). The Substack platform is especially good at facilitating this process thanks to its user-friendly social features (leave a comment on this post if you want to see for yourself!). And, because blog posts are usually edited more lightly than essays/news articles and churned out more quickly, this iterative process occurs at a reasonable clip.
So welcome to Irrational Actor, and I hope you will engage critically and thoughtfully with the ideas I express here. And please share your own ideas as well in the comments section. The more people that read and comment on these posts, the higher the quality of comment-section discourse, so please share this blog with friends and family if you think they would find it interesting!